Introduction
Have you ever heard someone say, “Virtual functions are slower than normal functions”? It’s a common refrain among C++ developers, but how slow are they, really? While virtual functions are fundamental to runtime polymorphism, they do introduce some costs—costs that might be negligible in many cases but significant in performance-critical applications. I’ve often wondered about the actual impact of virtual functions on performance, so I set out to explore it. This post extends my previous post about C++ dispatching. My goal wasn’t to prove or disprove the statement but to understand where these costs come from and how much they truly matter in real-world scenarios.
Mechanism and Impacts
Virtual functions are typically implemented using a vtable and a vptr. When a virtual function is called, the vptr is dereferenced to retrieve the actual function address from the vtable, and then the call is dispatched. For a more detailed explanation into how this works, I covered the details in this post.
This mechanism introduces several implications that you could imagine:
- The additional vtable and special stubs, (e.g., thunks) increases the overall binary size. This makes it harder for the CPU to keep relevant instructions in the cache, leading to more icache misses.
- The runtime lookup involves an extra jump, which introduces unavoidable overhead.
- Virtual calls prevent the compiler from inlining the function, which eliminates a major optimization opportunity. Additionally, branch prediction won’t help you, further pushing the code away from peak performance.
A Typical Scenario: Measuring Virtual Function Costs
The impact of any single factor is often hard to measure on its own. However, when multiple small impacts combine, their collective effect can be much larger than expected, significantly influencing overall performance. To explore this, I set up a very common case from our codebase: a collection of polymorphism objects.
std::vector<Base*> v;
This is a common scenario – we have a std::vector of pointers to Base and call a virtual function on each object sequentially.
Virtual vs Final vs Normal
We define the classes like this,
struct Base {
virtual double VirtualF() const noexcept { return 1.0; };
virtual double NonOverriddenF() const noexcept { return 1.0; };
virtual double FinalF() const noexcept final { return 1.0; };
double NormalF() const noexcept { return 1.0; };
};
struct Derived : public Base {
double VirtualF() const noexcept override { return 2.0; };
};
We insert several pointers to Derived objects into a std::vector and measure the cost of calling different types of functions: virtual functions (with and without overrides), final functions, and normal non-virtual functions. Keep in mind that all objects in the vector are instances of the Derived class.
For each type of function, the benchmark is executed as follows,
std::vector<Base*> v;
std::fill_n(std::back_inserter(v), NUM, new Base);
for (auto _ : state) {
for (auto ele: v) {
benchmark::DoNotOptimize(ele->VirualF());
}
}
I ran the benchmarks on my AMD Ryzen 5800X with GCC 13.2 compiled with the-std=c++20 -O3 flags. The results are as follows like,

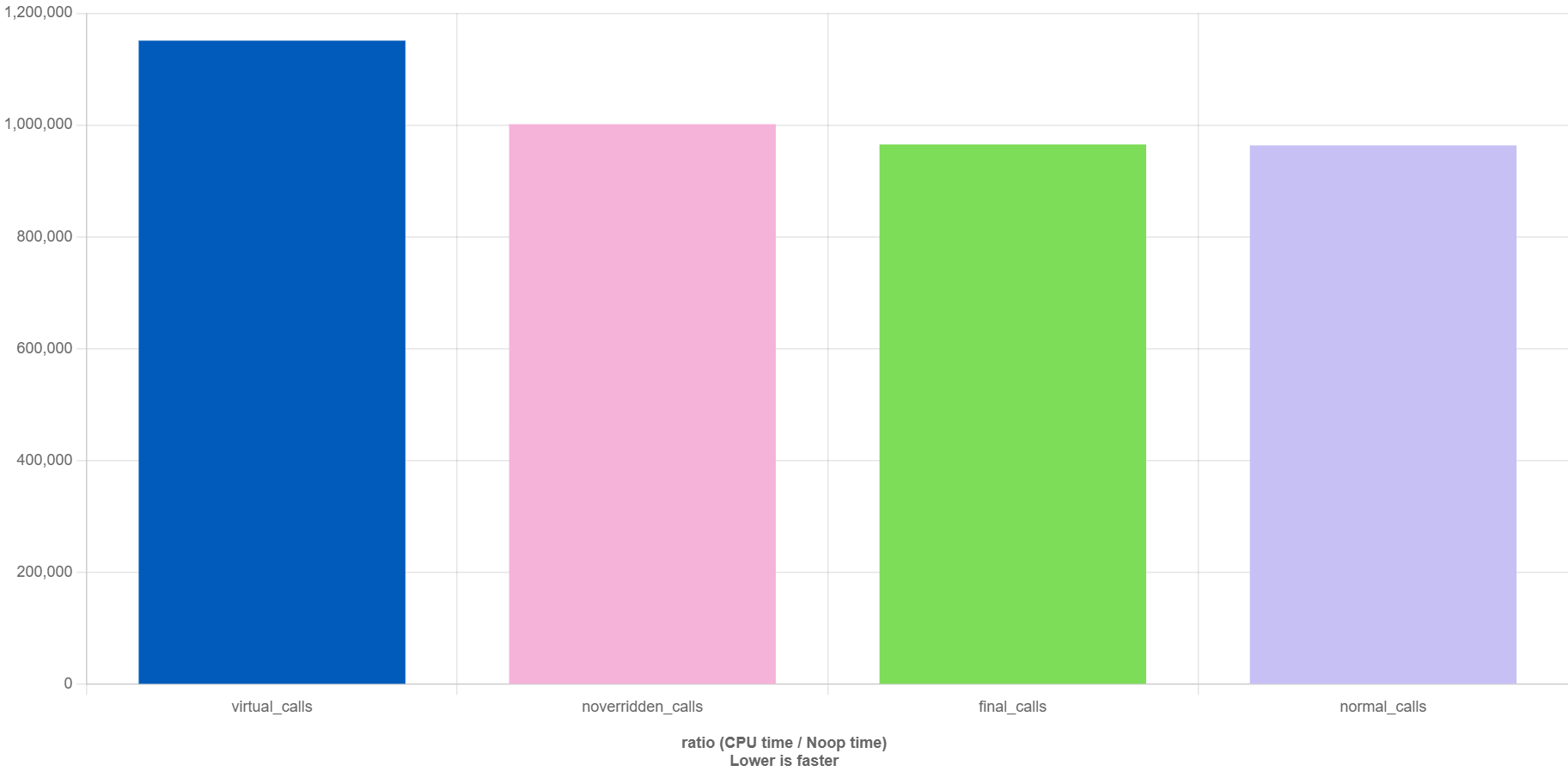
A few interesting conclusions from the chart,
- The final functions perform as effectively as the normal calls. Although declared as
virtual, markingBase::FinalFfinalguarantees that it cannot be overriden in derived classes. The compiler knows at the compile time that any call toFinalF, fromDerived, will be resolved toBase::FinalF. - The virtual calls are approximately 12x slower than normal functions in this case. Wow, it’s a significant difference! However, since our functions are extremely simple – just returning an integer – the cost of virtual functions is magnified.
- The most interesting point might be the performance of
NonOverriddenF(), it’s roughly 4x slower than normal functions, faster than virutal functions.
Thanks to perf, I can dive into the assembly and see how much time each instruction takes. This is a slightly different pattern from what you usually see with virtual function calls. Here’s the breakdown:
.L81:
movq 0(%rbp), %rdi ; Load object `pointer this` into %rdi
0.24% movq (%rdi), %rax ; Load the vtable pointer from the object into %rax
3.08% movq 8(%rax), %rax ; Get the function pointer for `Base::NonOverriddenF() const` (vtable offset 8)
49.51 cmpq $Base::NonOverriddenF() const, %rax ; Compare the function pointer in %rax with `Base::NonOverriddenF()` address
44.21% jne .L106 ; Jump if they are not equal (Impossible in our case)
addq $8, %rbp
cmpq %rbp, %rbx
jne .L81
.L106:
call *%rax ; Call the function pointed by %rax
movq %xmm0, %rax
addq $8, %rbp
cmpq %rbp, %rbx
jne .L81
jmp .L80
cmpq $Base::NonOverriddenF() const, %rax: This is the crucial comparison step. The compiler checks whether the function pointer in %rax matches the address of Base::NonOverriddenF() const. Since the object is likely an instance without overriding this function, this comparison should always be true.
Interestingly, because Base::NonOverriddenF() is a simple function, it is inlined here. Moreover, since its return value is not used, the compiler eliminates the actual function call entirely! This results in the function being “present” for the purpose of comparison, but it is never actually invoked during execution.
Slightly Improvement
To make this discussion more meaningful, I constructed a more practical example.
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_real_distribution<> dis(0.0, 100);
struct Base {
virtual double VirtualF() const noexcept { return dis(gen); };
virtual double NonOverriddenF() const noexcept { return dis(gen) + 0.1; };
virtual double FinalF() const noexcept final { return dis(gen) + 0.2; };
double NormalF() const noexcept { return dis(gen) + 0.3; };
};
struct Derived : public Base {
double VirtualF() const noexcept override { return dis(gen) + 0.4; };
};
I used a random generator here. Because it is not a pure function, the compiler cannot eliminate these calls, ensuring that every function invocation is actually performed.
 It turned out, virtual functions and non-overriden functions are around 1.2x and 1.1x slower than normal functions.
It turned out, virtual functions and non-overriden functions are around 1.2x and 1.1x slower than normal functions.
Input Pattern and Branch Predictions
In our previous case, all pointers pointed to the same type. However, in reality, instances of different types are often collected together, and this variability introduces significant challenges for branch prediction.
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_real_distribution<> dis(0.0, 100);
struct Base {
double NormalF() const noexcept { return dis(gen); }
virtual double VirtualF() const noexcept { return dis(gen); }
};
template <int V>
struct D : public Base {
double VirtualF() const noexcept override { return dis(gen) + static_cast<double>(V); }
};
std::vector<Base*> gen_data(int num, bool shuffle = false) {
std::vector<Base*> v;
std::fill_n(std::back_inserter(v), num / 3, new D<1>);
std::fill_n(std::back_inserter(v), num / 3, new D<2>);
std::fill_n(std::back_inserter(v), num / 3, new D<3>);
if (shuffle) {
std::random_device rng;
std::mt19937 urng(rng());
std::shuffle(v.begin(), v.end(), urng);
}
return v;
}
Basically, it’s similar to our previous case. I created three derived calsses, each evenly distributed in the vector. I measure the time it takes to call VirtualF on each object, both with and without shuffle the vector.
The results are as follows,
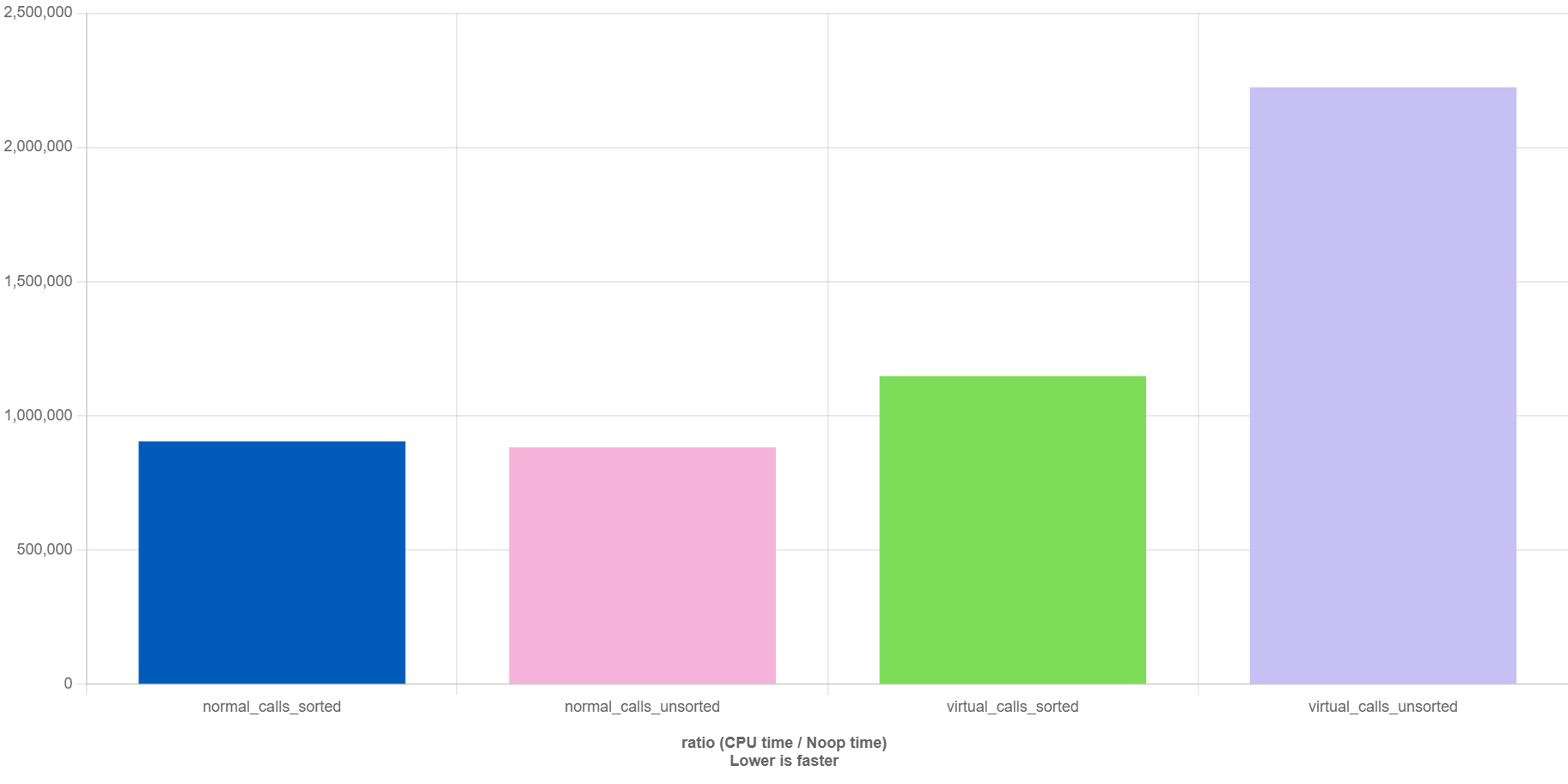
Normal calls are unaffected whether the vector is shuffled or not. However, shuffled(unsorted) virtual calls are 1.9x slower than sorted virtual calls! From the perf stats,
branch-misses # 22.14% of all branches
...
topdown-bad-spec # 47.1% bad speculation
The CPU struggled to predict the next instruction, causing significant stalls in execution, which is an indirect performance overhead incurred by virtual functions.
Conclusion
In summary, while virtual functions are essential for enabling polymorphism in C++, they introduce performance overhead, particularly due to vtable lookups and the inability to inline functions. This can cause noticeable slowdowns, especially in performance-critical applications with large collections of polymorphic objects. In such cases, careful design choices, like using final functions or avoiding unnecessary polymorphism, can help mitigate the overhead.
Always remember to base conclusions on benchmark results.