Overview
Iyengar111/NanoLog is a fast and lightweight C++11 logging library. It has only less than a thousand lines of code. It’s less famous than another eponymous version, and this repo seems not under maintenance any longer. I read the source code for learning. This post delves into its technique details.
Usage
#include "NanoLog.hpp"
int main()
{
nanolog::initialize(nanolog::GuaranteedLogger(), "/tmp/", "nanolog", 1);
// nanolog::initialize(nanolog::NonGuaranteedLogger(3), "/tmp/", "nanolog", 1);
LOG_INFO << "this is " << 42;
return 0;
}
There are two modes to set when initializing.
- Guaranteed logging, all messages are logged.
- Non-Guaranteed logging, some messages are dropped at extreme logging rates.
In either mode, messages are only written to files but not printed to the console.
Messages Buffer
Here is the definition of related macro LOG_INFO
#define LOG_INFO nanolog::is_logged(nanolog::LogLevel::INFO) && NANO_LOG(nanolog::LogLevel::INFO)
#define NANO_LOG(LEVEL) nanolog::NanoLog() == nanolog::NanoLogLine(LEVEL, __FILE__, __func__, __LINE__)
Than our statement
LOG_INFO << "this is " << 42;
will be expanded to
nanolog::is_logged(nanolog::LogLevel::INFO) && NANO_LOG(LEVEL) nanolog::NanoLog() == nanolog::NanoLogLine(nanolog::LogLevel::INFO, example.cc, main, 7) << "this is " << 42;
According to the operator precedence, << will be first evaluated. We take a look at the right part of the assignment first. A temporary NanoLogLine object is called. This class is in charge of the memory allocation and storing the message.
class NanoLogLine {
private:
size_t m_bytes_used;
size_t m_buffer_size;
std::unique_ptr < char [] > m_heap_buffer;
char m_stack_buffer[256 - 2 * sizeof(size_t) - sizeof(decltype(m_heap_buffer)) - 8 /* Reserved */];
};
Memory Allocation Strategy
Message data will be first stored into m_stack_buffer[] and allocated on the stack if necessary. If more space is required, a chunk of heap memory will be assigned to m_heap_buffer, which is nullptr when constructing.
void NanoLogLine::resize_buffer_if_needed(size_t additional_bytes)
{
size_t const required_size = m_bytes_used + additional_bytes;
if (required_size <= m_buffer_size)
return;
if (!m_heap_buffer)
{
m_buffer_size = std::max(static_cast<size_t>(512), required_size);
m_heap_buffer.reset(new char[m_buffer_size]);
memcpy(m_heap_buffer.get(), m_stack_buffer, m_bytes_used);
return;
}
else
{
m_buffer_size = std::max(static_cast<size_t>(2 * m_buffer_size), required_size);
std::unique_ptr < char [] > new_heap_buffer(new char[m_buffer_size]);
memcpy(new_heap_buffer.get(), m_heap_buffer.get(), m_bytes_used);
m_heap_buffer.swap(new_heap_buffer);
}
}
When the heap buffer is first allocated, its size is decided by the larger one between 512 and required_size. The buffer is growing by doubling the capacity if enough or resizing to the required size.
Encode
NanoLog encodes messages into raw bytes. NanoLogLine overloads its operator<< for certain types and encodes them inside.
NanoLogLine& operator<<(char arg);
NanoLogLine& operator<<(int32_t arg);
NanoLogLine& operator<<(uint32_t arg);
NanoLogLine& operator<<(int64_t arg);
NanoLogLine& operator<<(uint64_t arg);
NanoLogLine& operator<<(double arg);
NanoLogLine& operator<<(std::string const & arg);
template < size_t N >
NanoLogLine& operator<<(const char (&arg)[N]);
template < typename Arg >
typename std::enable_if < std::is_same < Arg, char const * >::value, NanoLogLine& >::type
operator<<(Arg const & arg);
template < typename Arg >
typename std::enable_if < std::is_same < Arg, char * >::value, NanoLogLine& >::type
operator<<(Arg const & arg);
Most << do the similar thing, int32_t for example,
NanoLogLine& NanoLogLine::operator<<(int32_t arg)
{
encode < int32_t >(arg, TupleIndex < int32_t, SupportedTypes >::value);
return *this;
}
template < typename Arg >
void NanoLogLine::encode(Arg arg, uint8_t type_id)
{
resize_buffer_if_needed(sizeof(Arg) + sizeof(uint8_t));
encode < uint8_t >(type_id);
encode < Arg >(arg);
}
template < typename Arg >
void NanoLogLine::encode(Arg arg)
{
*reinterpret_cast<Arg*>(buffer()) = arg;
m_bytes_used += sizeof(Arg);
}
When we’re logging messages, the first encode is called. Besides the arguments, an additional one-byte length type_id is inserted. It’s used to flag what the type of arg is. Without this flag, raw bytes can’t be reverted to the original look.
How about strings? They don’t have a fixed size. So when copying strings, the null-terminator is also included to indicate the end.
Decode
When writing to a file, i.e. std::ofstream, the raw bytes are decoded.
void NanoLogLine::stringify(std::ostream & os, char * start, char const * const end)
{
if (start == end)
return;
int type_id = static_cast < int >(*start); start++;
switch (type_id)
case 0:
stringify(os, decode(os, start, static_cast<std::tuple_element<0, SupportedTypes>::type*>(nullptr)), end);
return;
...
}
template < typename Arg >
char * decode(std::ostream & os, char * b, Arg * dummy)
{
Arg arg = *reinterpret_cast < Arg * >(b);
os << arg;
return b + sizeof(Arg);
}
It uses the first byte to determine the type Arg and then dereferences the pointer to get the value.
decode for strings is specialized. char s are sent to os one by one until the end.
while (*b != '\0')
{
os << *b;
++b;
}
Asynchronous Logging
Back to the macro. Whenever the messages in a statement are buffered, the NanoLogLine object is moved into a global nanologger. The only use of NanoLog is the overloaded assignment operator for accessing the global variable.
bool NanoLog::operator==(NanoLogLine & logline)
{
atomic_nanologger.load(std::memory_order_acquire)->add(std::move(logline));
return true;
}
Here, the author uses an atomic pointer to the global object, which I don’t see any necessity. When a nanologger is constructed, the time we call the initialize function, a thread is spawned for polling available NanoLoggers and writing them to files. This technique is called asynchronous logging, a common optimization method in modern logging libraries. It’s a traditional MPSC(Multiple Producer, Single Consumer) paradigm. The key we’ll talk about here is the different internal data structures in the two modes. A ring buffer for non-guaranteed and a queue for guaranteed mode. These two data structures are required to implement only two interfaces, for input and output, separately.
void push(NanoLogLine && logline);
bool try_pop(NanoLogLine & logline);
Ring Buffer
A ring buffer, a.k.a circular buffer, is a fixed-size memory and behaves like a connected end-to-end queue. The concurrency solution is to use two shared variables m_write_index and m_read_index, only m_write_index is atomic since the reader is always single-thread. Each slot(item below) in the queue contains a field for user data, NanoLogLine here, and a written flag, a spin-lock implemented by std::atomic_flag.
When a writer is to push,
- a unique index is acquired to get the slot to be written
- acquire the lock
- write and set the
writtenflag - release the lock
void push(NanoLogLine && logline) override
{
unsigned int write_index = m_write_index.fetch_add(1, std::memory_order_relaxed) % m_size;
Item & item = m_ring[write_index];
SpinLock spinlock(item.flag);
item.logline = std::move(logline);
item.written = 1;
}
try_pop is similar, get the slot, and check if it’s been written. The subtle difference is that the m_read_index is incremented only when written is 1.
This implementation is not lock-free, since it uses a spin-lock when accessing the slot. However, its performance is reasonably good.
Uncontened Performance
The uncontended performance is important for consideration. Some lock-free data structures help here, by reducing the number of expensive atomic operations in the uncontended fast-path, or avoiding a syscall. Here the atomic operation based spin-lock costs less compared to std::mutex or other pthread calls if under Linux.
Contended Performance
Imagine what happens when the access is heavily contented? All writers don’t check if the slot has been written or been read, so unread data may be overwritten by other threads, and log messages are lost. Also, it can’t guarantee the ordering of messages since an overwritten message is written after the message in the next slog. When a huge number of writer threads and a reader thread are accessing the same slot, due to unpromised fairness in C++ standard, the reader thread might starve. See the following, different arrows meaning operations on different threads.
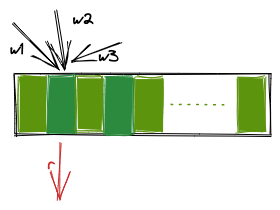
But fortunately, the extreme contended case only occurs when the writer thread number is more than the slot size, which is at least 4096. What we worry about rarely happens. I think it’s a trade-off for lower writing costs.
Bounded Queue
Since every message is promised to be kept and should not be blocked when pushed into the queue, the queue uses a dynamic memory allocation strategy. It has a queue<unique_ptr<Buffer>>, which holds the messages. Both read and write need two indexes, one for the current buffer and another for the current position in the buffer. Like the ring-buffer design, only the write indexes are required to be atomic.
class QueueBuffer {
std::queue< std::unique_ptr < Buffer > > m_buffers;
std::atomic<Buffer * > m_current_write_buffer;
Buffer * m_current_read_buffer;
std::atomic < unsigned int > m_write_index;
std::atomic_flag m_flag;
unsigned int m_read_index;
};
The Buffer is a fixed memory and holds an array of std::atomic<unsigned int> for every slot to record if it’s been written or read, these atomics are initialized to 0.
When a NanoLogLine is pushed, it gets a unique index to write through atomically m_write_index self-increment, if this index is valid, a NanoLogLine instance is move constructed via placement new, and the written flag is being set to 1. If this slot happens to be the last available one, the queue is asked to create another Buffer and reset the write indexes. If this index is not valid, which means the current Buffer is already full, this push will keep retrying until m_write_index is valid.
When trying to pop one message, if the current read buffer index, m_current_read_buffer, is nullptr (by default), it gets the front one of m_buffers when the queue is not empty. And use the self-incremented m_read_index to get the corresponding slot, then pop the slot if the written flag is set. When this read index happens to be the last one, which means the whole buffer is already been read, the queue pop out the front one. Due to each element being a unique_ptr, when poped out the useless memory will be deallocated. And the m_current_read_buffer is set back to nullptr.
Whenever the queue, m_buffers is changed, including popping out, pushing, and getting the front element, a spin-lock is used for synchronization. This behavior is only happening when a buffer is being finished writing or reading, so this lock will not be contented heavily.
Garbage collection is a non-negligible cost here, so the author makes the Buffer large enough to 8MB to mitigate the effects. But it’s still a huge cost when messages are logged too frequently.
Other Details
Cache-friendly
NanoLog is cache-friendly in two ways.
Firstly, false sharing occurs when multiple variables share the same cache line, and threads modifying independent variables within that cache line cause cache invalidations for the other threads. In NanoLog, although reader and writer threads can now operate on their own counters, the variables may still share the same cache line. So whenever a thread updates its own counter, it may result in a forced cache line reload. NanoLog inserts dummy char array paddings between these two variables to mitigate this problem.
Secondly, NanoLog inserts paddings to force the item in the slot to be aligned to 64, the typical cache line size. Ideally, different items will not reside in the same cache line, and the cost of unnecessary memory synchronization is reduced. However, since C++17 whether an over-aligned type is supported by std::allocator is still implementation-defined (impossible before C++17). There still are possibilities that two items share the same cache line.
String Literals
NanaLog introduces a class string_literal_t to avoid the unnecessary copy of string literals, similar to std::string_view in C++17. Compared to std::string, it only copies the pointer when constructing with a string literal. Since these literals are stored in a static area, so no worry about lifetime comes in.
struct string_literal_t
{
explicit string_literal_t(char const * s) : m_s(s) {}
char const * m_s;
};
Filter Messages under Threshold
If you have read my previous post about glog, you may remember glog will store every message no matter what log level they are, they are filtered only when flushing. NanoLog uses a different strategy, the trick is to use a && operator to ignore the following messages if the log level is lower. Recall the expanded macro. Here nanolog::is_logged is a function comparing the received log level with the threshold and return a bool. If the it returns false, which means this log level in under threshold, the following operand will not be executed.
nanolog::is_logged(nanolog::LogLevel::INFO) && NANO_LOG(LEVEL) nanolog::NanoLog() ==
TypeList
Strictly speaking, it’s not a kind of optimization, but I want to spend some time explaining the trick. It’s used here to distinguish different types. Here is the definition of SupportedTypes
typedef std::tuple < char, uint32_t, uint64_t, int32_t, int64_t, double, NanoLogLine::string_literal_t, char * > SupportedTypes;
SupportedTypes is a type alias to std::tuple including all supported types.
To find the location of a specific type T in SupportedTypes, metafunction TupleIndex is introduced, which uses a recursive formulation. The recursion stops Only when type T is the same as the first type of std::tuple<U, Types...>, otherwise, it’ll continue comparing with the sub tuple std::tuple<Types...>. This technique is common in template programming.
template < typename T, typename Tuple >
struct TupleIndex;
template < typename T, typename ... Types >
struct TupleIndex < T, std::tuple < T, Types... > >
{
static constexpr const std::size_t value = 0;
};
template < typename T, typename U, typename ... Types >
struct TupleIndex < T, std::tuple < U, Types... > >
{
static constexpr const std::size_t value = 1 + TupleIndex < T, std::tuple < Types... > >::value;
};
// find index in compile-time
TupleIndex<uint32_t, SupportedTypes>::value;
Drawbacks
There are also some shortcomings of this design. Functionally, It doesn’t support logging self-defined classes because no viable operator<<(NanoLogLine&, Foo) is found. The only way to support it is to define implicit conversion operators to the supported types. Also, it doesn’t support writing to multiple files and controlling file size some essential functions. Performantly, I have pointed out some edge cases where the whole program gets slowed down or totally blocked.